Why Elixir/OTP doesn't need an Agent framework: Part 1
The LLM ecosystem has seen an explosion of frameworks, particularly in JavaScript and Python. While popular, these frameworks often serve two purposes: they either hide language limitations around concurrency or task orchestration, or they abstract "common" LLM operations. But do we really need this abstraction? Usually we would be better off building simple, bespoke solutions.
I've found, and from what I've seen the general consensus online as well is, that a lot of these frameworks work well enough for a POC but as the project grows and needs for custom behaviours arise, it's failing to meet the challenge.
langchain isn't a library, it's a collection of demos held together by duct tape, fstrings and prayers. It doesn't provide building blocks, it provides someone's fantasy of one line of code is all you need. And it mainly breaks apart if you're using anything but openai.
Disastrous_Elk_6375 on reddit
I'd only use it to quickly validate some ideas, PoC style to test the waters, but for sanity and production you need to pick alternatives or write your own stack.
The chain of messages
I don't think we should move the abstraction too far from the actual chain of messsages. It's the the basic unit of operation with LLMs and it doesn't seem to be going away - especially if you rely on idiosyncracies of specific models, like Claude Prefilling.
I've been working with LLMs for a while now (check out my AI swarm powered relationship coach Reyote) and I've found that real magic happens when one manipulates and actively manages the chain, tailoring it for specific tasks and not giving the LLM more information than it absolutely needs. For instance, I'm a big fan of aider and have been studying their prompting techniquies. The power it gives us comes from constantly manipulating the chain for specific tasks (for example custom architect and code prompts, or conversation summarization when the conversation becomes too long.)
A case for Elixir
Apart from working with LLMs I've been working with Elixir/OTP for even longer and have fallen in love with the language, and the power, thoughtfulness and expressiveness behind it. At first glance, Elixir doesn't seem to have much in terms of library support for building LLM workflows or agentic behavior, but in these series of posts I'd like to make a case that it's just because the building blocks are all there already. This is not specific to only iteracting with LLMS, that is often the case with Elixir - most people just prefer to roll their own using the wonderful building blocks Elixir and the OTP library give you.
In the next few posts I'd like to showcase how Elixir can be used to interact with LLMs and build complex and effective solutions. We'll start simple, by going through the article "Building effective AI agents" by Anthropic, showcasing how simple Elixir makes implementing them, and over the course of the series increasing the complexity of solutions.
Let's start
Only library we'll be needing for now is InstructorLite. It's pretty basic in its functionality, where it allows you to take in a chain of messages and define an output schema, usually by using Structured outputs.
Workflow 1: Prompt chaining
Here's how Prompt chaining is explained in the article:
When to use this workflow: This workflow is ideal for situations where the task can be easily and cleanly decomposed into fixed subtasks. The main goal is to trade off latency for higher accuracy, by making each LLM call an easier task.
We'll be implementing the following scenario:
- Based on an input an outline for a potential article will be generated
- Using this outline we'll generate a full article
- We'll translate this article to another language (keep in mind the translation doesn't need the full context)
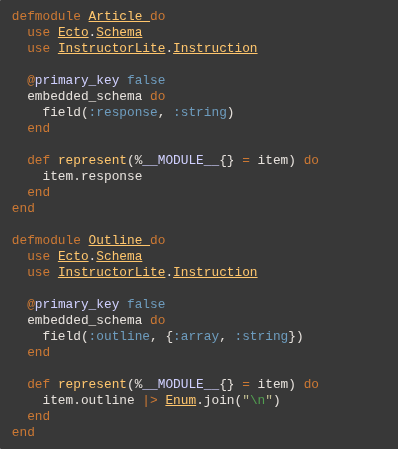
Let's first generate the Response types we need, in this case an Article and an Outline. Keep in mind we're not doing any sanity checks in these examples, even though the InstructorLite library supports it.
defmodule Article do
use Ecto.Schema
use InstructorLite.Instruction
@primary_key false
embedded_schema do
field(:response, :string)
end
def represent(%__MODULE__{} = item) do
item.response
end
end
defmodule Outline do
use Ecto.Schema
use InstructorLite.Instruction
@primary_key false
embedded_schema do
field(:outline, {:array, :string})
end
def represent(%__MODULE__{} = item) do
item.outline |> Enum.join("\n")
end
end
Now let's create a simple workflow using just Elixir's with statements. While simple, it actually offers a lot of flexibility, as we have access to the chain snapshot at every stage and we can choose whether we take in the whole history (as is the case with topic -> outline -> article) or we can ignore it and take only what we need (in the case of the translation).
defmodule ArticleBuilder do
def generate_content(topic) do
initial_messages = [
%{role: :system, content: "You are an expert at crafting SEO friendly blog articles"}
]
with {:outline, {:ok, _outline, outline_messages}} <-
{:outline, create_outline(initial_messages, topic)},
{:article, {:ok, article, _article_messages}} <-
{:article, create_article(outline_messages)},
{:translation, {:ok, translated_article, _translated_messages}} <-
{:translation, translate_to(article, "german")} do
{article, translated_article}
else
{stage, {:error, _err}} -> "Error in stage #{stage}"
end
end
def create_outline(messages, topic) do
messages =
messages ++
[
%{
role: :user,
content: "Please generate an outline of an article about the following topic #{topic}"
}
]
run_query(messages, Outline)
end
def create_article(messages) do
messages =
messages ++
[%{role: :user, content: "Please generate a full article based on the provided outline"}]
run_query(messages, Article)
end
def translate_to(%Article{response: content}, language \\ "spanish") do
messages = [
%{
role: :system,
content:
"You are an expert polyglot translator, that provides article translations. Do not make any changes to the content other than translating it"
},
%{
role: :user,
content: "Please translate the following article into #{language}:\n\n#{content}"
}
]
run_query(messages, Article)
end
defp run_query(messages, response_model) do
{:ok, response} =
InstructorLite.instruct(
%{messages: messages},
response_model: response_model,
adapter_context: [api_key: System.get_env("OPENAI_API_KEY")]
)
{:ok, response,
messages ++ [%{role: :assistant, content: response_model.represent(response)}]}
end
end
We can run this process with something like this. Obviously in a real-world scenario we'd provide the LLM with a lot more context, but you'd be surprised how far just this simple approach can take you.
ArticleBuilder.generate_content("Impact of AI on white collar jobs")
Workflow 2: Routing
The Anthropic article describes the routing pattern as so:
The scenario we'll be using to showcase Elixir is this:
- We'll give a topic with some context about an article we want to produce
- A router will classify the topic into predefined categories, along with relevant search terms
- A custom search tool will perform a query (we'll be mocking this)
- A specific LLM prompt will be invoked per-category, generating a summary and key points.

Let's start as before - defining the outputs we'll be working with.
Pay attention to the Classifier - it's really simple to implement ourselves, but along with the classification we can ask it to output extra information, like relevant search queries for the topic. Relying on predefined routers would limit such functionality, with no real benefit.
defmodule TopicClassification do
use Ecto.Schema
use InstructorLite.Instruction
@primary_key false
embedded_schema do
field(:domain, Ecto.Enum, values: [:entertainment, :science, :finance])
field(:search_terms, :string)
end
end
defmodule Summary do
use Ecto.Schema
use InstructorLite.Instruction
@primary_key false
embedded_schema do
field(:summary, :string)
field(:key_points, {:array, :string})
end
end
Next let's actually build the workflow. Take note how Elixir makes everything fit together well using just pattern matching.
defmodule TopicAnalyzer do
def analyze_topic(topic) do
initial_messages = [
%{role: :system, content: "You are an expert at classifying topics into domains."}
]
with {:classify, {:ok, classification, classification_messages}} <-
{:classify, classify_topic(initial_messages, topic)},
{:search, {:ok, search_data}} <-
{:search, search_by_domain(classification)},
{:summarize, {:ok, summary}} <-
{:summarize, create_summary(classification, search_data)} do
{:ok, summary}
end
end
defp classify_topic(messages, topic) do
messages = messages ++ [
%{role: :user, content: "Classify this topic and provide specific search terms: #{topic}"}
]
run_query(messages, TopicClassification)
end
defp search_by_domain(%TopicClassification{domain: :finance, search_terms: terms}) do
# Mock Yahoo Finance data
{:ok, %{
"stock_price" => "$156.42",
"daily_change" => "+2.3%",
"trading_volume" => "12.3M",
"recent_news" => [
"Company announces new product line",
"Q3 earnings beat expectations"
]
}}
end
defp search_by_domain(%TopicClassification{domain: :science, search_terms: terms}) do
# Mock arXiv data
{:ok, %{
"papers" => [
%{
"title" => "Recent Advances in #{terms}",
"abstract" => "This paper explores...",
"citations" => 42
},
%{
"title" => "Novel Approaches to #{terms}",
"abstract" => "We present...",
"citations" => 17
}
]
}}
end
defp search_by_domain(%TopicClassification{domain: :entertainment, search_terms: terms}) do
# Mock Twitter data
{:ok, %{
"tweets" => [
%{
"text" => "Can't believe the latest news about #{terms}! #trending",
"likes" => 1234
},
%{
"text" => "#{terms} just changed the game forever",
"likes" => 5678
}
],
"sentiment" => "mostly positive"
}}
end
defp create_summary(classification, search_data) do
messages = [
%{
role: :system,
content: get_domain_prompt(classification.domain)
},
%{
role: :user,
content: """
Create a summary of this #{classification.domain} data about #{classification.search_terms}:
#{Jason.encode!(search_data, pretty: true)}
"""
}
]
run_query(messages, Summary)
end
defp get_domain_prompt(:finance) do
"""
You are a financial analyst. Create a market summary focusing on:
- Price movements and their significance
- Trading patterns
- News impact on the market
- Future outlook
"""
end
defp get_domain_prompt(:science) do
"""
You are a scientific researcher. Create a research summary focusing on:
- Key findings from papers
- Research trends
- Significance of citations
- Future research directions
"""
end
defp get_domain_prompt(:entertainment) do
"""
You are an entertainment analyst. Create a trend summary focusing on:
- Social media reaction
- Public sentiment
- Trending opinions
- Cultural impact
"""
end
defp run_query(messages, response_model) do
case InstructorLite.instruct(
%{messages: messages},
response_model: response_model,
adapter_context: [api_key: System.get_env("OPENAI_API_KEY")]
) do
{:ok, response} ->
{:ok, response, messages ++ [%{role: :assistant, content: inspect(response)}]}
error -> error
end
end
end
Wrapping Up
I hope these examples showcase how we can build sophisticated LLM workflows using simple Elixir mechanisms. While our implementation might seem basic - just pattern matching and with statements - don't be fooled by the simplicity. This approach of composing small, focused functions and passing message chains through them can take us surprisingly far.
The beauty of this approach lies in its transparency - we can see exactly how our LLM interactions flow, what context is being maintained, and where we might want to add error handling or logging. No magic, no hidden state, just clear functional transformations.
In the next entries of this series, we'll explore more complex patterns from Anthropic's guide, gradually introducing OTP primitives like Tasks for parallelization, GenServers for stateful operations, and Agents for shared state. But remember - reach for these tools only when their benefits outweigh the added complexity.
Stay tuned for Part 2, where we'll see how Tasks can help us implement Anthropic's parallelization pattern, allowing us to run multiple LLM operations concurrently while maintaining clean, readable code