Why Elixir/OTP doesn't need an Agent framework: Part 2
In part one of this series we've been working through the patterns the excellent article "Building effective AI agents" by Anthropic.
In this post, we'll continue implementing those patterns, and as before, the main thing I'd like to showcase is how easy and elegant implementing these patterns can be in Elixir, and more importantly, how we don't need advanced frameworks to work with LLMs.
By keeping the level abstraction low and working with the chain of messages directly I hope to show how we can make some pretty complex and creative solutions. Many of these Lang-type frameworks make simple things sound complex, and maybe if we dig a bit beneath the surface you'll feel encouraged to come up with creative solutions that fit your exact needs.
If you haven't yet, I'd recommend having a look at the first part of the series as we introduce the technologies we'll be using there.
Let's start
To preempt some feedback, some of these examples could be implemented using GenServers or something more stateful, but I'm trying to keep this simple.
Workflow 3: Parallelization
Sectioning: Breaking a task into independent subtasks run in parallel.
Voting: Running the same task multiple times to get diverse outputs.
This is a similar pattern as the ones we covered before, however instead of running tasks sequentially we can identify areas where certain areas don't have dependencies on each others' results and we can execute them in parallel.
This perfectly showcases Elixir's strengths. We'll take an existing solution and with minor tweaks we'll enable a whole new capability.
So, what are we implementing - a demo system (but pretty capable with a few tweaks) inspired by the Stanford's STORM project. The STORM project aims to generate a comprehensive report on a topic by having a group of LLMs take different perspectives. Each agent has the ability to search the internet and by discussing a topic they synthesize a report. It produces great results, and just watching their conversation is very informative.
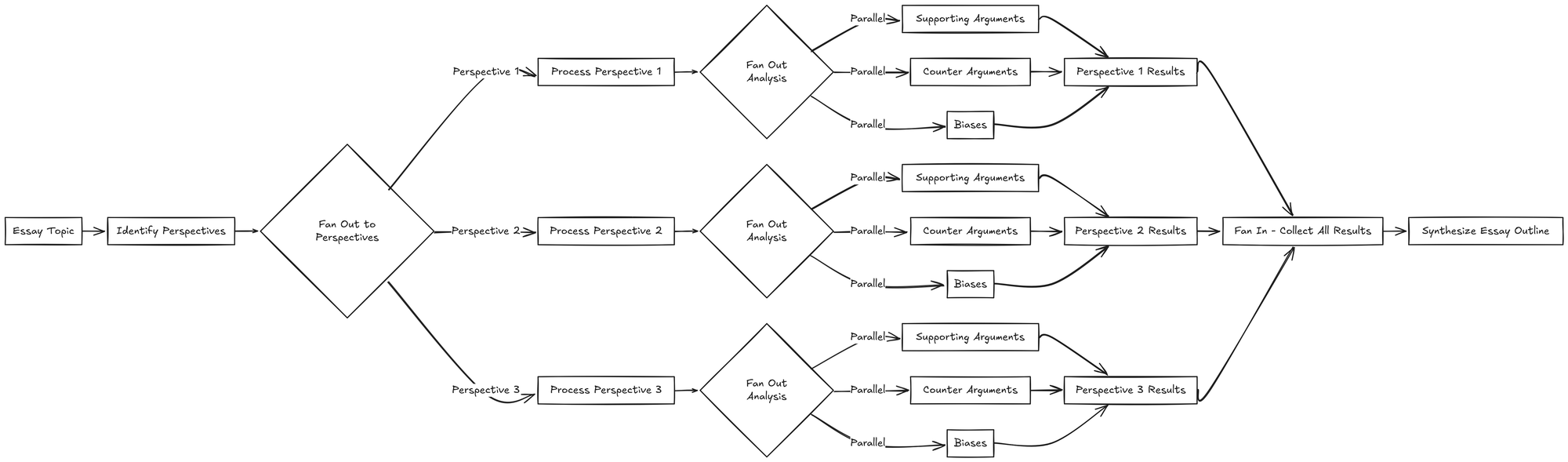
I hope this example isn't too ambitions for a blog post, and I'll try to condense things as much as possible. Here's what we'll be implementing: an essay writing helper that will take a topic, dynamically determine through which perspectives it should be analyzed, and then spawn for each perspective an analysis of it's strengths, weaknesses, supporting facts and biases.
Here are the steps:
- Initial Analysis: LLM breaks down the topic into key perspectives/angles (e.g., economic, social, ethical, historical precedents)
- Parallel Argument Generation: For each perspective, spawn parallel tasks:
- Task 1: Generate strong supporting arguments
- Task 2: Generate strong counter-arguments
- Task 3: Find relevant evidence/examples
- Task 4: Identify potential biases in common arguments
- Synthesis: Combine the strongest arguments, counter-arguments, and evidence into a balanced essay outline and notes
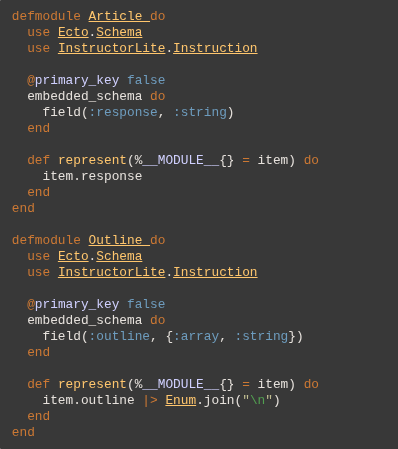
So let's define what objects we'll be working with.
defmodule PerspectiveList do
use Ecto.Schema
use InstructorLite.Instruction
@all_perspectives [
:economic, :social, :ethical, :political, :historical,
:technological, :environmental, :cultural, :legal,
:philosophical, :scientific, :psychological, :global, :local
]
@primary_key false
embedded_schema do
field(:perspectives, {:array, Ecto.Enum}, values: @all_perspectives
)
end
end
defmodule ArrayResponse do
use Ecto.Schema
use InstructorLite.Instruction
@primary_key false
embedded_schema do
field(:perspective, :string)
field(:analysis_type, Ecto.Enum, values: [:support, :counter, :biases])
field(:response, {:array, :string})
end
end
defmodule EssayOutline do
use Ecto.Schema
use InstructorLite.Instruction
@primary_key false
embedded_schema do
field(:title, :string)
field(:introduction, :string)
field(:sections, {:array, :string})
field(:conclusion, :string)
field(:balanced_approach_notes, :string)
end
end
We've defined a list potential perspectives through which a topic can be evaluated. The list of options is hardcoded - this is optional, but I recommend doing so in these types of operations.
We have a generic ArrayResponse, which we basically use to force the LLM to output it's response as a list of items. It's a simplified implementation for demo purposes, we could also create specialized structs for each use case.
And finally we have a struct in which we can store our outline and notes.
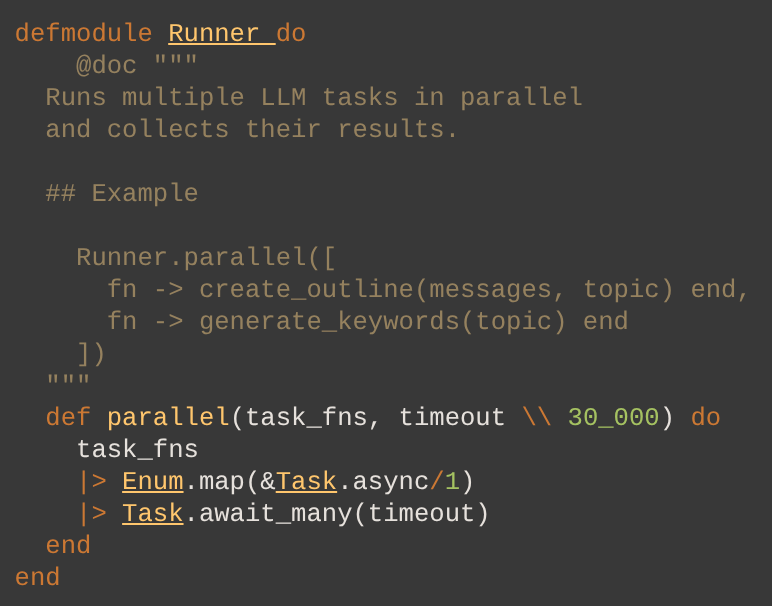
Building on our implementation from part one, we need only minor modifications to enable parallelization. We're still keeping with the basic structure - focusing on the message chain and using InstructorLite to structure our responses, but we will need to run things in parallel this time. Probably a big refactor needed, right? Actually no, with a minor modification - introducing the Task module, it's almost trivial to run things concurrently, and await their results.
Let's add a minor helper that will take a list of function callbacks and run them together, and await their results.
defmodule Runner do
@doc """
Runs multiple LLM tasks in parallel and collects their results.
## Example
Runner.parallel([
fn -> create_outline(messages, topic) end,
fn -> generate_keywords(topic) end
])
"""
def parallel(task_fns, timeout \\ 30_000) do
task_fns
|> Enum.map(&Task.async/1)
|> Task.await_many(timeout)
end
end
And that's mostly it. I'm sure you can see a clear direction for us forming.
Note: In the interest of brevity, I'm simplifying things a little, but not too much. For production code you might want a dedicated task supervisor, maybe some error handling and/or retry mechanisms.
Let's complete the exercise. We'll have the LLM dynamically decide which perspectives would suit the topic. For each perspective we'll dynamically spawn a task, which itself will dynamically spawn tasks for each of the dimensions we've discussed (supporting facts, counter, search and bias). After this fan out is complete, we'll collect all the results and have one final task propose an outline with some notes.
Here's the full implementation. Hopefully it's self explanatory, and I've added some comments to guide you.
defmodule EssayTopicAnalysis do
def run_analysis(topic) do
# Generate a list of 3-5 perspectives
{:ok, perspectives, _perspectives_messages} = get_perspectives(topic)
# For each perspective create an async task (which in turn will create several more)
analyses = perspectives.perspectives
|> Enum.map(fn perspective ->
# we're creating a callback function with a closure for each perspective
fn -> provide_perspective_analysis(topic, perspective) end
end)
|> Runner.parallel()
# Generate the final outline with all the collected analyses
outline = generate_outline(topic, analyses)
# Return both the detailed analyses and the synthesized outline
%{
analyses: analyses,
outline: outline
}
end
def get_perspectives(topic) do
messages = [
%{role: :user,
content: "I'm writing an essay about: #{topic}. Suggest 3-5 perspectives through which to analyze it"}
]
run_query(messages, PerspectiveList)
end
def provide_perspective_analysis(topic, perspective) do
[{:ok, supportive, _}, {:ok, counter, _}, {:ok, biases, _}] = Runner.parallel([
fn -> generate_supportive_arguments(topic, perspective) end,
fn -> generate_counter_arguments(topic, perspective) end,
fn -> analyze_biases(topic, perspective) end
])
# NOTE: I didn't want to mock search results again, as it would just take
# up space in the already long demo. You can imagine, as in the previous
# example, the initial perspective generator could generate search terms
# to use with something like https://exa.ai
{perspective, {supportive, counter, biases}}
end
def generate_outline(topic, analyses) do
# Format the analyses into a structured format for the LLM
formatted_analyses = analyses
|> Enum.map(fn {perspective, {supportive, counter, biases}} ->
"""
## #{perspective} Perspective:
### Supportive Arguments:
#{format_points(supportive.response)}
### Counter Arguments:
#{format_points(counter.response)}
### Potential Biases:
#{format_points(biases.response)}
"""
end)
|> Enum.join("\n\n")
messages = [
%{role: :system,
content: "You are an expert essay outline creator who can synthesize multiple perspectives into a coherent structure."},
%{role: :user, content: """
I'm writing an essay on the topic: "#{topic}"
I've analyzed this topic from multiple perspectives.
Here are the detailed analyses:
#{formatted_analyses}
Based on these analyses, please create:
1. A comprehensive essay outline with main sections and subsections
2. Brief notes for each section highlighting key points to address
3. Suggestions for a balanced approach that considers multiple perspectives
"""
}
]
{:ok, outline, _} = run_query(messages, EssayOutline)
outline
end
defp format_points(points) do
points
|> Enum.map(fn point -> "- #{point}" end)
|> Enum.join("\n")
end
def generate_supportive_arguments(topic, perspective) do
messages = [
%{role: :user,
content: "I'm writing an essay about: #{topic}. Suggest 3-5 points that are supportive or in favor, from the #{perspective} perspective"}
]
run_query(messages, ArrayResponse)
end
def generate_counter_arguments(topic, perspective) do
messages = [
%{role: :user,
content: "I'm writing an essay about: #{topic}. Suggest 3-5 points that are negative or in counter, from the #{perspective} perspective"}
]
run_query(messages, ArrayResponse)
end
def analyze_biases(topic, perspective) do
messages = [
%{role: :user,
content: "I'm writing an essay about: #{topic}. Suggest 3-5 biases in my topic or premise, from the #{perspective} perspective"}
]
run_query(messages, ArrayResponse)
end
defp run_query(messages, response_model) do
case InstructorLite.instruct(
%{messages: messages},
response_model: response_model,
adapter_context: [api_key: System.get_env("OPENAI_API_KEY")]
) do
{:ok, response} ->
{:ok, response, messages ++ [%{role: :assistant, content: inspect(response)}]}
error -> error
end
end
end
EssayTopicAnalysis.run_analysis("Universal Basic Income: A Necessary Evolution of Social Welfare")
And there we have it (actually try running the code with different topics, I'm finding the results it creates very interesting).
This is a demo project - but with some extra tools (internet search), I could see this being a pretty useful project (or even a SaaS?). I'm sure you can think of a few additional steps that would make it even more useful, but I hope you can see how building out a relatively complex workflow like this is not that difficult if we keep close to the chain of messages and have good tools.
No visual workflow builders or LangChain frameworks needed, all with maximum flexibility and control.
Workflow 4: Orchestrator-workers
We've already implemented most of this pattern in our essay analysis example. The initial perspective identification acts as an orchestrator, determining which angles to explore, while the parallel analysis tasks function as workers.
The orchestrator-workers pattern simply formalizes this relationship, where:
- A central coordinator (orchestrator) breaks down a complex task
- Specialized workers handle specific subtasks
- Results are collected and synthesized by the orchestrator
This is a natural fit for Elixir's concurrency model - we're already spawning tasks and collecting their results. No special frameworks needed, just functions calling functions with the appropriate structure.
To extend our essay example into a more explicit orchestrator-workers pattern, we might simply add more specialized analysis types or incorporate external tools like search engines as additional "workers" in our parallel processing pipeline.
The key insight is that in Elixir, the boundary between these patterns is fluid - our parallelization example already contains elements of orchestration, showing how these concepts naturally emerge from Elixir's design.
Workflow 5: Evaluator-optimizer
This workflow is particularly effective when we have clear evaluation criteria, and when iterative refinement provides measurable value.
We're finally getting to agentic behavior? Shall we use GenServers, Agents, something else?
Actually, if we break the problem down it's just 2 functions recursively calling each other. One function generating a proposal and another one evaluating it and providing feedback.
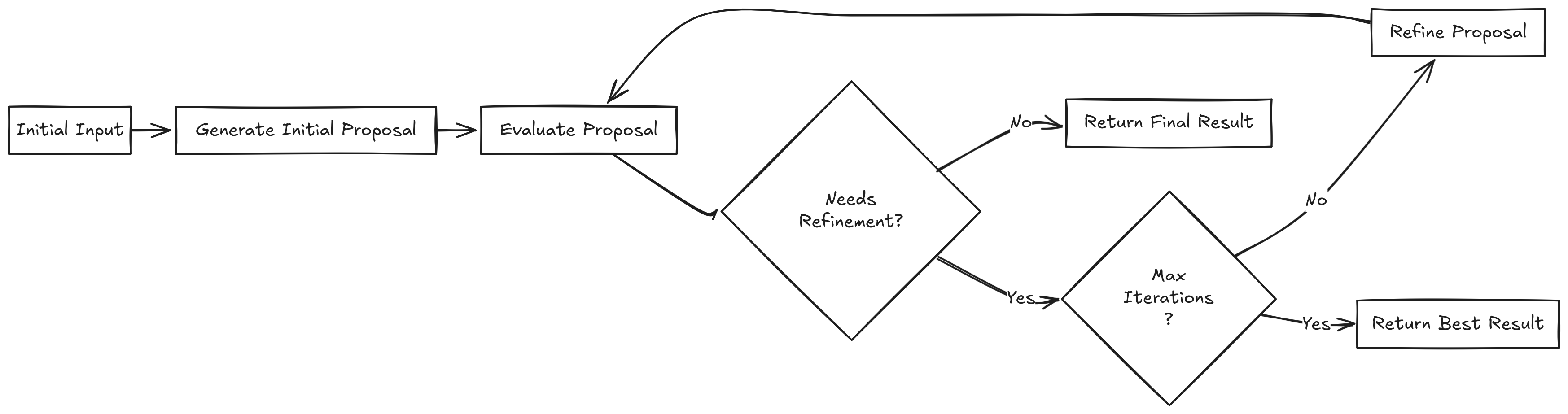
Note: It's important to be careful when passing the chain around - especially with Anthropic models. If a final message is an assistant message, it will consider the message to be the start of a response you expect (see Claude Prefilling.) Some providers allow a message to have an extra field - name to distinguish between different actors, but please look at the documentation for specifics.
Let's actually build something concrete - a landing page content generator. We'll task it with coming up with sections for a landing page based on our requirements, it will generate a list of sections with proposed content and an evaluator will suggest modifications. It's important to limit this process with a maximum number of iterations, for both practical and cost purposes.
As usual, let's define our response types.
defmodule LandingPageSection do
use Ecto.Schema
use InstructorLite.Instruction
@section_types [
:hero, :features, :benefits, :how_it_works,
:testimonials, :pricing, :comparison, :faq,
:about_us, :cta_primary, :contact_form, :footer
]
@primary_key false
embedded_schema do
field(:section_type, Ecto.Enum, values: @section_types)
field(:headline, :string)
field(:subheadline, :string)
field(:content, :string)
field(:cta_text, :string)
end
end
defmodule LandingPage do
use Ecto.Schema
use InstructorLite.Instruction
@primary_key false
embedded_schema do
field(:page_title, :string)
field(:target_audience, :string)
embeds_many(:sections, LandingPageSection)
end
end
defmodule Feedback do
use Ecto.Schema
use InstructorLite.Instruction
@primary_key false
embedded_schema do
field(:feedback, {:array, :string})
field(:needs_refinement, :boolean)
end
end
One thing to note - a struct can embed other structs, which we see in the LandingPageSection example. Great thing about this approach is that we can use Ecto.Changesets to provide validation of data provided by the LLM, and pass it back to the LLM to correct itself. This article is getting long already, so let's leave it for later.
Here's our implementation, showcasing how Elixir pattern matching and recursion makes the whole process straightforward.
We start by generating an initial proposal and feedback and recurisively call the iterate_on_landing_page function until we either get feedback which isn't asking for refinement or we exceed the @max_iterations, in which case we return the latest revision.
defmodule LandingPageProposalGenerator do
@max_iterations 4
def propose_landing_page(project_info) do
initial_chain = [
%{role: :system, content: "You are an expert marketer, specializing in building landing pages that convert very well"},
%{role: :user, content: "Please propose a landing page for the following project: #{project_info}"}
]
{:ok, proposal, proposal_messages} = run_query(initial_chain, LandingPage)
{:ok, feedback, _feedback_messages} = provide_feedback(proposal_messages)
iterate_on_landing_page(project_info, proposal_messages, proposal, feedback, 0)
end
def iterate_on_landing_page(
project_info,
messages,
latest_proposal,
%{needs_refinement: true} = feedback,
iteration) when iteration < @max_iterations do
# Add the feedback as a user message to guide refinement
refinement_messages = messages ++ [
%{
role: :user,
content: """
Based on this feedback, please improve the landing page structure:
FEEDBACK:
#{Enum.join(feedback.feedback, "\n")}
Create an improved version that addresses these points.
"""
}
]
# Generate a refined proposal
{:ok, refined_proposal, new_messages} = run_query(refinement_messages, LandingPage)
# Get feedback on the refined proposal
{:ok, new_feedback, feedback_messages} = provide_feedback(new_messages)
# Continue the iteration process with the refined proposal
iterate_on_landing_page(
project_info,
new_messages,
refined_proposal,
new_feedback,
iteration + 1
)
end
# if no new refinement is necessary or we've reached max iterations,
# return the latest proposal
def iterate_on_landing_page(
_project_info, _messages, latest_proposal, _feedback, _iteration) do
latest_proposal
end
def provide_feedback(messages) do
# In order to simplify things, we'll work on the original chain
# but we will replace the system message and convert all assistant
# messages to user messages
messages = messages
|> Enum.map(fn
%{role: :system} -> %{
role: :system,
content: "You are an expert marketer, giving feedback on a proposed landing page plan, based on a project plan. Be pedantic, think of questions a visitor might have and make sure they're answered clearly."}
%{role: :assistant, content: content} -> %{
role: :user,
content: "PROPOSED STRUCTURE: #{content}"}
msg -> msg
end)
messages = messages ++ [
%{role: :user,
content: "Provide detailed feedback on the proposed structure. Only say that it doesn't require refinement if you have 0 objections."}]
run_query(messages, Feedback)
end
defp run_query(messages, response_model) do
case InstructorLite.instruct(
%{messages: messages},
response_model: response_model,
adapter_context: [api_key: System.get_env("OPENAI_API_KEY")]
) do
{:ok, response} ->
{:ok, response, messages ++ [%{role: :assistant, content: inspect(response)}]}
error -> error
end
end
end
And there you have it. You could see it in action by calling something like this:
LandingPageProposalGenerator.propose_landing_page("""
Reynote.com is an AI powered relationship coach.
It features full therapy sessions based on integrative therapy principles,
a swarm of specialized AIs, journaling, progress tracking and more.
What makes it unique is that it's meant to be used as a couple,
where the AI has access to both perspectives and can serve as a bridge
between, clearing misunderstandings and helping the relationship grow.
""")
This pattern is very powerful, as it allows the LLMs to think through complex task. It is especially powerful when combining several different LLMs - a strong reasoning model to generate the main task and a smaller one to provide feedback.
Make sure to iterate on the prompts while building your solution to make sure the feedback loop isn't too eager to provide feedback and knows when to stop, but that is something we always deal with LLMs.
I hope you're feeling inspired to build something of your own, and that this article provided some mental and technical building blocks to help you.
So far we've been working with the basics, relying on structured outputs for a clear interface between our code and LLMs, without touching more advanced topics like tool calls or agents with state or memory. We'll start exploring those topics in the next few articles.